Tech Blog
Viewing Jupyter notebooks on the command line
It’s often useful to be able to view the contents of Jupyter notebooks from the command line, without starting a Jupyter notebook or JupyterLab server and navigating to it in your web browser.
This is convenient when you’re already in a terminal in the correct directory, and even more so when the notebook is on a machine to which you may only have SSH access (for example an EC2 instance), and don’t want to have to start an SSH tunnel.
This is trivial for other literate programming formats for scientific computing, such as R Markdown and Pweave: these formats use lightweight markup languages that don’t need special rendering to be legible. As such it’s enough to print the raw file contents with a pager such as less, or even with cat.
This isn’t the case for Jupyter notebooks. Internally, Jupyter notebooks are JSON documents with a strict schema. Notebooks can contain images and other binary data, which if printed with cat will fill your terminal with unintelligible Base64 encoded data.
As a result, instead of printing the notebook contents straight to the terminal, we need to do some rendering. nbconvert helps with this: it’s a tool to convert Jupyter notebooks to other formats, including rich formats such as HTML and PDF, and plain text formats including Markdown. The latter is most useful here, as Markdown is by design readable in source form, without noisy markup or formatting instructions.
As an example, we’ll use a Jupyter notebook derived from an example in the PyTorch documentation.
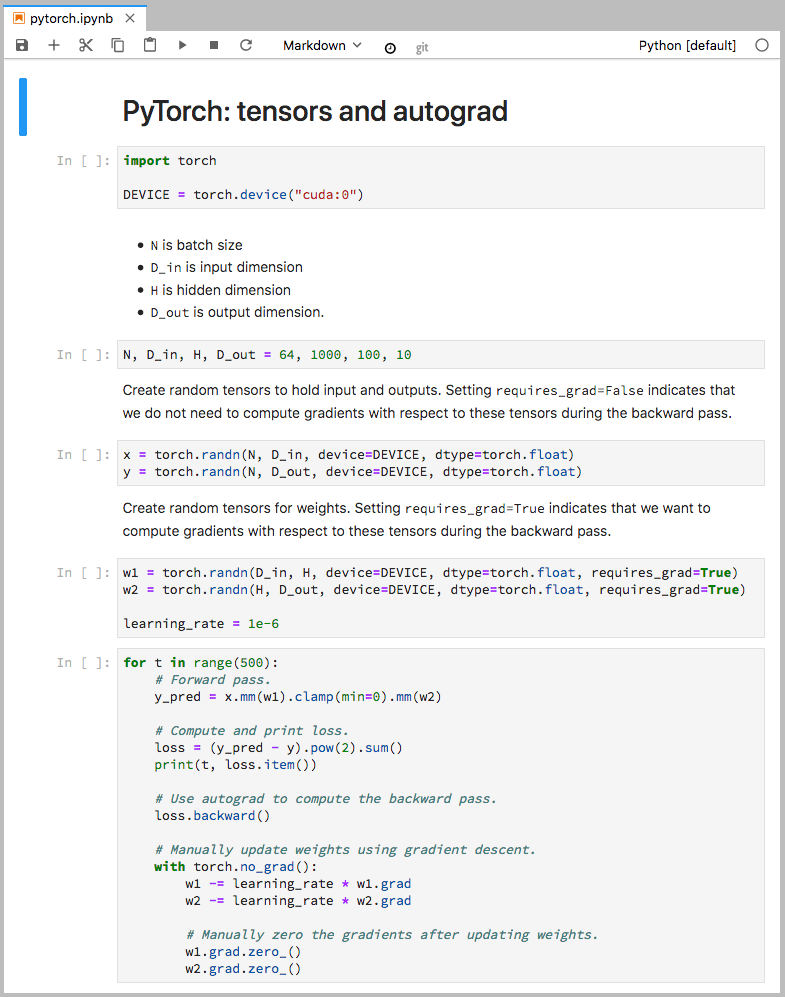
We can use nbconvert to convert the notebook to Markdown, printing the output to standard output rather than to a file with the same stem as the input file but .md extension, as follows:
$ jupyter nbconvert --stdout --to markdown pytorch.ipynb
[NbConvertApp] Converting notebook pytorch.ipynb to markdown
# PyTorch: tensors and autograd
```python
import torch
DEVICE = torch.device("cuda:0")
```
* `N` is batch size
* `D_in` is input dimension
* `H` is hidden dimension
* `D_out` is output dimension.
```python
N, D_in, H, D_out = 64, 1000, 100, 10
```
Create random tensors to hold input and outputs. Setting `requires_grad=False`
indicates that we do not need to compute gradients with respect to these
tensors during the backward pass.
...nbconvert writes the header [NbConvertApp] Converting notebook pytorch.ipynb to markdown to standard error, while it writes the document body to standard output, so we can suppress outputting the former by redirecting standard error (this syntax is for Bourne-like shells such as bash. If you’re not using such a shell, change the redirection as appropriate):
jupyter nbconvert --stdout --to markdown pytorch.ipynb 2>/dev/nullThis is already much more readable than the raw JSON document, but we can improve legibility further for code snippets by applying syntax highlighting. We will do this by piping the output of nbconvert to pygmentize, a command line interface to the Pygments syntax highlighting library. Pygments is a dependency of nbconvert, so if you’ve followed the commands up to here, you already have it installed.
Because we’re piping text to pygmentize on standard input, it cannot determine the language for which to apply syntax highlighting, so we specify it using the -l flag:
jupyter nbconvert --stdout --to markdown pytorch.ipynb 2>/dev/null | pygmentize -l mdFinally, we can pipe the output of pygmentize to a pager such as less so that we can scroll through notebooks that exceed a single terminal in length.
jupyter nbconvert --stdout --to markdown pytorch.ipynb 2>/dev/null | pygmentize -l md | lessThis is now a longer command than we would like to type each time we use it, so let’s create a shell script, which also implements basic input validation:
#!/bin/sh
set -eu
readonly EX_USAGE=64
readonly EX_NOINPUT=66
usage() {
echo "usage: $(basename "$0") <notebook>"
}
if [ $# -ne 1 ]; then
usage
exit $EX_USAGE
fi
if [ "$1" = -h ] || [ "$1" = --help ]; then
usage
exit
fi
if [ ! -f "$1" ]; then
echo "$(basename "$0"): $1: No such file"
exit $EX_NOINPUT
fi
jupyter nbconvert --stdout --to markdown "$1" 2>/dev/null | pygmentize -l md | lessAfter saving this as nbcat or similar in a directory on your shell’s command search path, we can call it with the path to a Jupyter notebook to view the notebook in plain text with syntax highlighting:
