Tech Blog
Machine learning systems should use data aware orchestrators

By automating simple decisions and assisting with complex ones, machine learning will transform how organisations operate. In ten years, high-functioning organisations will have networks of connected models that provide a layer of intelligence as critical to the organisation as business intelligence tools are today.
But the weightier the decisions, the more important the burden of proof. Training models in notebooks is not good enough. Passing spreadsheets around via email will not provide an appropriate audit trail. If a machine learning system is making decisions (or even supporting decisions), it should be subject to the same degree of scrutiny as a human.
Part of the solution will come from tools like model explainability: knowing what features went into making a particular prediction. But part of the solution will also come from better management of data and models. Being able to answer questions like “when was this data or prediction generated?”, or “what version of the model was used in this prediction?”, or “what data was that model trained on?” should become par for the course when making important decisions.
Of course, this sounds trivial. But as decision making in organisations becomes increasingly complex, with lots of connected models built by different teams, tracking the metadata to answer these questions becomes ever cumbersome.
The problem with orchestrators
Traditionally, organisations have relied on orchestrators like Airflow to manage complex workflows. These orchestrators take heterogeneous tasks and allow programmers to specify the dependencies between them.
Orchestrators allow teams to independently develop self-contained tasks, then wire them together. They allow for the expressing of complex flows, like “avoid running this if this step has failed”. Likewise, they give developers and systems administrators a control plane where they can see the status of their pipelines, replacing a mess of cron jobs and webhooks that were difficult to audit or observe.
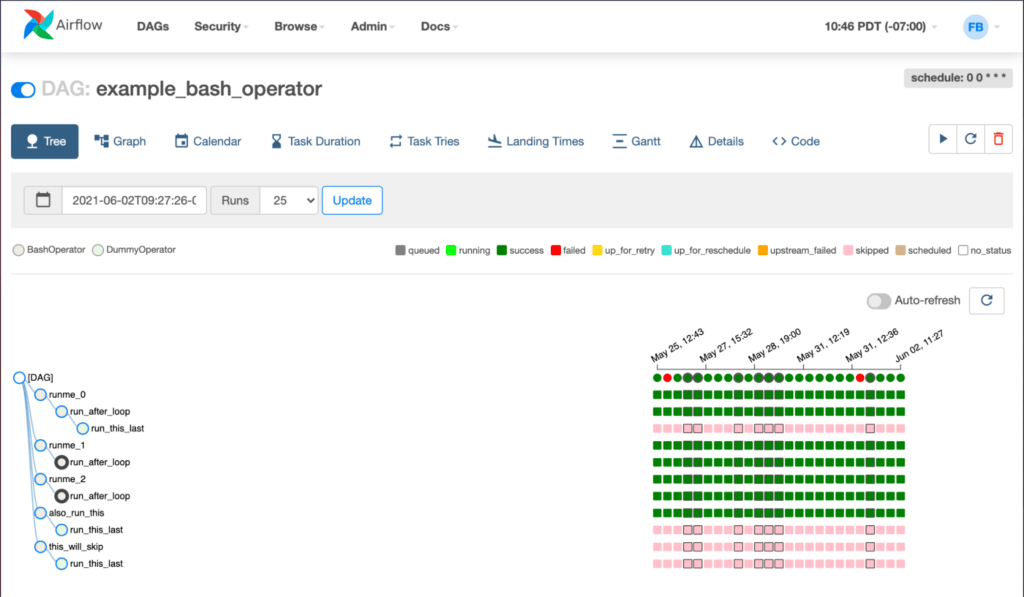
Image from the Airflow documentation, Apache License.
Until recently, orchestrators have primarily focussed on dependency management and on separating concerns, both between different development teams, and between development and systems administration. But these orchestrators are missing a key abstraction for data management. In machine learning or decisioning systems, tasks typically generate datasets (or sometimes models) that are then used downstream. These datasets and models are the dependencies, rather than the bits of code that generate the data and model.
Let’s make this concrete with a simple system: we imagine loading data, transforming it to build features, and training a model from those features. The dependency chain in this system is most naturally expressed in terms of assets – the model depends on the features, which depends on the raw data.

In traditional orchestrators like Airflow, this dependency chain is implicitly represented by the dependency between tasks – a task to train the model depends on a task to transform the data. If a dataset needs to be generated and saved for a downstream task, it is up to the code in the task to serialise it for downstream consumption. The downstream task is then responsible for loading it. Thus, the fact that data is passed between tasks is completely hidden from the orchestrator.
Airflow makes it easy to answer questions like “what step needs to happen before when?” or “what step failed in my pipeline?” or “where do I need to restart?“. But to answer questions like “what features was this model trained on“, it requires inspecting the internals of the build features step to see how it serialises data.
Data first orchestrators, like Dagster, Prefect, and Kedro, recognise that the key dependency between each of these steps is data. Thus, the data passed between these steps should be treated as a first class citizen.
This allows for the tying of datasets or assets generated by the pipeline to individual runs of the model, as well as answering questions like “what dataset was this trained on?” or “which of these datasets is stale?”.
We use Dagster extensively as part of Frontier, to support complex training pipelines.
How can Dagster be aware of data flows?
For data dependencies to be treated explicitly, they must be declared. In Dagster, this happens through the Python API. For instance, the simple pipeline described earlier would be declared as:

Tasks in the graph (ops in Dagster parlance) are then wired by passing data explicitly between them.

Arbitrary additional metadata can be tracked along with the asset that is generated.
Dagster provides a mechanism – IO managers – to manage both how the assets are passed into the task, and what happens with the assets generated by the task.
Declaring data dependencies explicitly allows Dagster to represent data lineage, to track how metadata changes between runs, and depending on the IO manager used, to fully version data generated in each run.
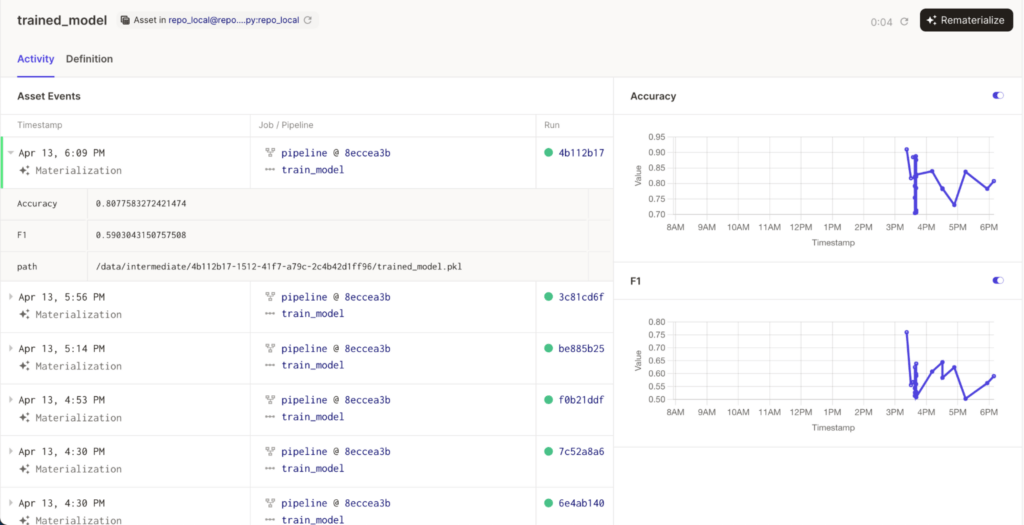
How does Frontier manage data with Dagster?
Frontier provides data scientists with the concept of projects, which encapsulate the data, code, and outputs related to a particular machine learning use case for an organisation. Within projects, data scientists have access to an AI development and deployment environment.
Projects contain an object store that is accessible both from the development and the deployment environment. When we run Dagster in production (and pre-production), the data generated by intermediate steps in the graph is stored in this object store, under a prefix that uniquely identifies this run. Thus, all the assets generated by the graph are fully versioned, and can be traced back to a particular run.
This way has two benefits:
• data and model traceability, lineage, and reproducibility: even when source systems change (and these are typically not in our control), we have the full lineage and all the versions of the data that went into a model or a set of decisions. This allows us to track every decision the model makes all the way back to source data, and, through our explainability capability, track why the system made that decision.
• We can run longitudinal studies to understand in depth how the system behaves over time: since we have all the data for all the runs (albeit in a compressed format), seeing how a particular dataset evolved over time can be done by just fetching the output of a particular node, for each run, into a Jupyter notebook and running an ad-hoc analysis.
This is only the beginning. The abstractions afforded by Dagster open up many possibilities, such as:
•a simplified version of the asset dependency graph that explains the architecture of the decision intelligence system to our customers.
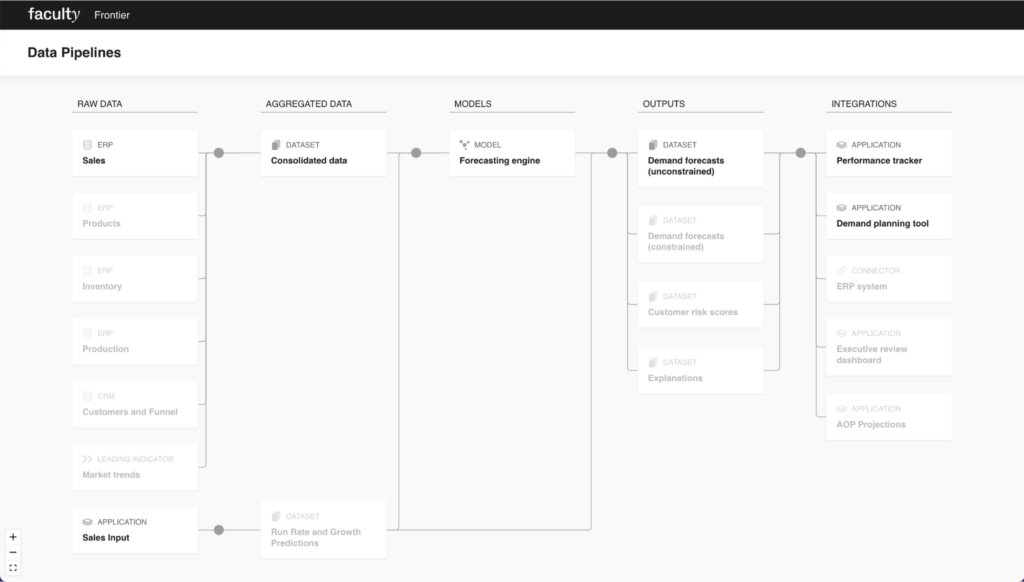
• a data catalogue that both allows data scientists to programmatically fetch a version of a particular asset (e.g. “I want the model that was generated from this particular transformed dataset”, or “I want the latest version of the model”), and that allows analysts to interact with the generated data (e.g. through a SQL-like interface, or maybe through integrating business intelligence tools like Superset).
• automatically tracking metadata generated during a run in Frontier’s experiment tracking feature.
It’s easy to get excited by the technical elegance of Dagster and the abstractions it gives us. But mostly, we are excited by the opportunity it gives us to build fully observable, traceable decision intelligence systems that deliver outlier performance for the organisations we work with.
To read more about Dagster, we suggest reading the excellent documentation on the website. Contact us to hear more about how Frontier can help your organisation.